NPU 멀티 코어 활용#
Overview#
모빌린트 NPU 는 아래 4개의 코어 협업 모드 (이하 코어 모드) 를 지원합니다. 사용자 매뉴얼 및 튜토리얼에서는 이해를 돕기 위한 의도로 가장 직관적인 코어 모드 인 Single 모드를 주로 활용하지만, 사용하고 계신 제품, 그리고 수행하고자하는 딥러닝 모델 태스크에 따라 더 적절한 코어 모드 가 존재합니다. 적절한 코어 모드 를 선택해 사용하면 큰 성능상 이점을 누릴 수 있습니다.
지원하는 코어 모드는 아래와 같습니다.
중요
코어 모드는 컴파일 단계에서 지정할 수 있습니다. 이미 컴파일된 MXQ를 보유중이실 경우 지정된 코어 모드 외에는 사용할 수 없습니다. 지정된 코어 모드는 mobilint-cli mxqtool 을 활용해 확인하실 수 있습니다.
원하시는 모드를 사용하기 위해선
직접 원하시는 모드로 컴파일 하거나,
해당 모드가 포함된 MXQ 파일을 사용하세요.
시작에 앞서, NPU 의 개괄적인 내부 구조를 이해할 필요가 있습니다. 기본적으로 모빌린트 NPU 의 각 코어 (Local Core) 는 독립적으로 한 개의 모델을 단독 수행할 수 있는 가장 작은 주체라고 이해하면 됩니다. 그리고 이 Local Core 들이 모여 클러스터를 이루게 됩니다. 클러스터에는 뒤에 설명할 Multi/Global4,8 Mode의 작업을 중재하기 위한 글로벌 코어 (Global Core) 가 추가로 존재합니다. Global Core 는 Multi/Global4,8 Mode 의 복잡한 작업을 중재하는 역할을 합니다. 이 내부 구조는 사용하고 계신 모빌린트 NPU 제품마다 다릅니다. 이를 그림으로 나타내면 아래와 같습니다:
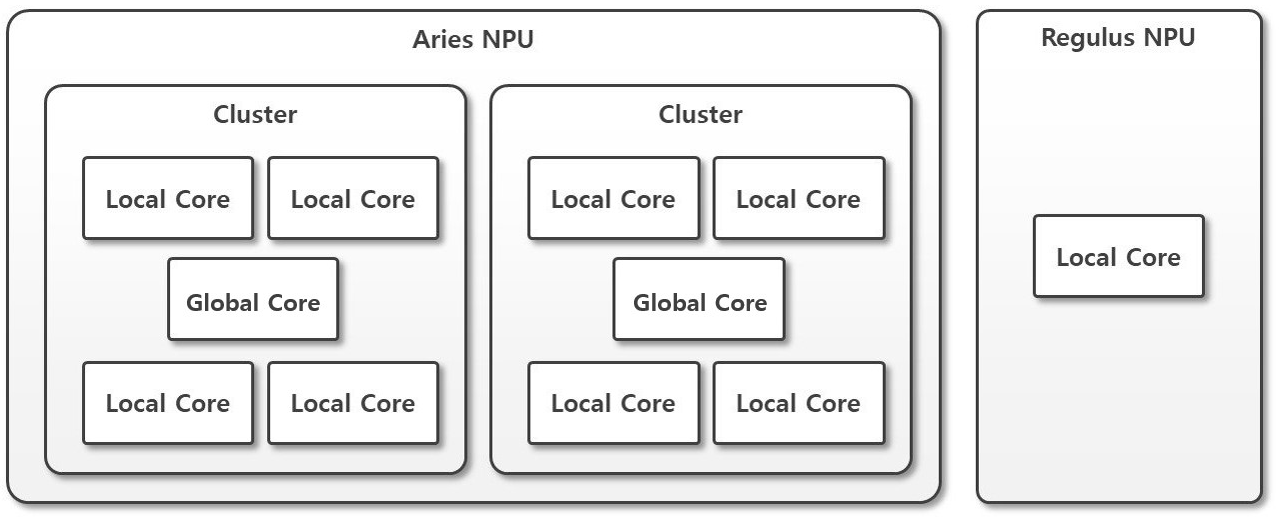
모빌린트 NPU 제품별로 사용 가능한 코어 모드가 다릅니다. 이는 위 NPU 제품별 내부 구조에 따른 특징으로, Global Core 의 존재 유무에 따라 자연스럽게 발생합니다. 즉, Local Core 가 하나 뿐인 REGULUS 제품은 Multi/Global4,8 Mode 기능을 제공하지 않습니다.
Product |
Single Mode |
Multi Mode |
Global4,8 Mode |
|---|---|---|---|
ARIES |
O |
O |
O |
REGULUS |
O |
X |
X |
지금부터 대표적인 멀티 코어 제품인 ARIES 를 기준으로 각 코어 모드를 설명합니다.
Single Mode#
가장 직관적인 모드로, 개별 Local Core 가 독립적으로 활동하는 모드입니다. 사용자는 사실상 개별 코어에 추론 요청을 전달하여 결과를 일일히 받아와 원하는 작업을 마치게 됩니다. 8 개의 코어에서 독립적인 작업을 할 수 있으므로, 8 개 코어에 쉴 새 없이 일을 할당하면 최고의 성능 (Throughput) 을 낼 수 있습니다.
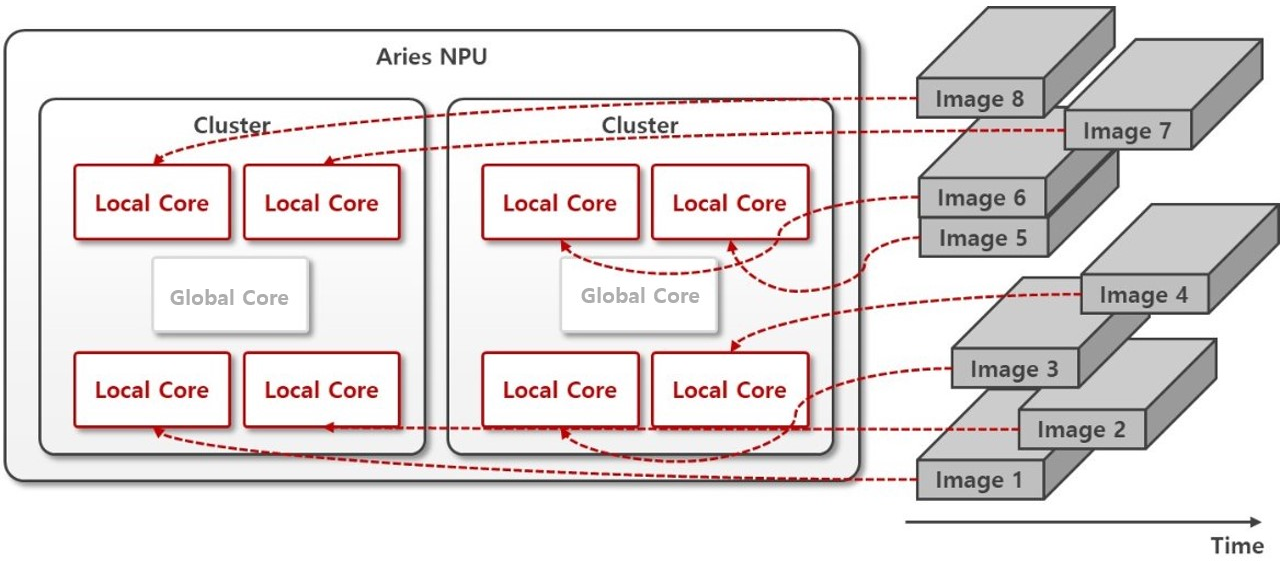
유의사항 : 기능 검증에 있어서는 사용하기 가장 편하고 직관적이나, 쉴 새 없이 요청을 보내는 매커니즘 설계가 필요합니다. 대표적으로 Multithreading/Async IO 등 다수 코어에 추론 요청을 동시에 요청하는 적절한 매커니즘을 사용자가 설계하지 않으면 추론 워크로드를 완전 순차 처리하여 사실상 한 개의 코어만 지속 사용하므로, 성능 면에서 비효율적일 수 있습니다. Multithreading/Async IO 는 소프트웨어공학의 보편적인 설계 패턴으로, Advanced Usage 나 관련 자료를 참고하여 설계합니다.
## Compilation stage
# Generate MXQ Model with Single-core Inference Scheme
from qubee import mxq_compile
mxq_compile(
...
inference_scheme="single" # Technically, this line can be omitted.
...
)
## Runtime stage with python
# Run Single-core Type Model
from maccel import Accelerator, Model, ModelConfig, CoreId, Cluster, Core
MXQ_PATH = "resnet50_single.mxq"
acc = Accelerator()
# Technically, these lines can be omitted - begin
mc = ModelConfig()
mc.set_single_core_mode(
core_ids=[
CoreId(Cluster.Cluster0, Core.Core0),
CoreId(Cluster.Cluster0, Core.Core1),
CoreId(Cluster.Cluster0, Core.Core3),
CoreId(Cluster.Cluster1, Core.Core2),
CoreId(Cluster.Cluster1, Core.Core3),
]
)
# end
model = Model(MXQ_PATH, mc) # If you omitted ModelConfig, erase the argument mc as well.
model.launch()
# model.infer(...)
// Runtime stage with C++
#include "maccel/maccel.h"
const char* MXQ_PATH = "resnet50_single.mxq";
int main() {
mobilint::StatusCode sc;
mobilint::ModelConfig mc;
auto acc = mobilint::Accelerator::create(sc);
if (!sc) exit(1);
if (!mc.setSingleCoreMode({
{mobilint::Cluster::Cluster0, mobilint::Core::Core0},
{mobilint::Cluster::Cluster0, mobilint::Core::Core1},
{mobilint::Cluster::Cluster0, mobilint::Core::Core3},
{mobilint::Cluster::Cluster1, mobilint::Core::Core2},
{mobilint::Cluster::Cluster1, mobilint::Core::Core3},
})) {
exit(1);
}
auto model = mobilint::Model::create(MXQ_PATH, mc, sc);
if (!sc) exit(1);
model->launch(*acc);
// auto result = model->infer();
}
Multi Mode#
Multi 모드는 배치 처리에 최적화된 모드로, 4 개의 Local Core 들로 이루어진 Cluster 단위로 동작합니다. 글로벌 코어가 개입된 클러스터 내 로컬 코어들의 협력을 통해 4배치 처리에 최적화된 연산을 수행합니다.

활용처
통상적인 Batch 처리와 같이 NPU 추론 로직을 구성하고 싶을 경우
Multithreading/Async IO 없이 4-batch 단위에서의 높은 성능 (Throughput) 을 내고 싶을 경우
## Compilation stage
# Generate MXQ Model with Multi-core Inference Scheme
from qubee import mxq_compile
mxq_compile(
...
inference_scheme="multi"
...
)
## Runtime stage with python
# Run Multi-core Type Model
from maccel import Accelerator, Model, ModelConfig, CoreId, Cluster, Core
MXQ_PATH = "resnet50_multi.mxq"
acc = Accelerator()
mc = ModelConfig()
mc.set_multi_core_mode([Cluster.Cluster0, Cluster.Cluster1])
model = Model(MXQ_PATH, mc)
model.launch()
# model.infer(...)
// Runtime stage with C++
#include "maccel/maccel.h"
const char* MXQ_PATH = "resnet50_multi.mxq";
int main() {
mobilint::StatusCode sc;
mobilint::ModelConfig mc;
auto acc = mobilint::Accelerator::create(sc);
if (!sc) exit(1);
if (!mc.setMultiCoreMode({
mobilint::Cluster::Cluster0,
mobilint::Cluster::Cluster1,
})) {
exit(1);
}
auto model = mobilint::Model::create(MXQ_PATH, mc, sc);
if (!sc) exit(1);
model->launch(*acc);
// auto result = model->infer();
}
Global Modes#
한 개의 데이터를 여러 코어가 협심하여 처리하는 추론 방식입니다. 예를 들어, 특히 큰 데이터를 처리해야하는 무거운 모델의 경우 입력 데이터를 나눠 처리하면 성능상 이득 (Latency) 을 얻을 가능성이 높은 경우 활용됩니다. Global Mode 는 클러스터 내의 모든 Local Core 를 사용하는 방식으로 제공되고 있으며, Global4 Mode, Global8 Mode 이라는 이름으로 구분됩니다.
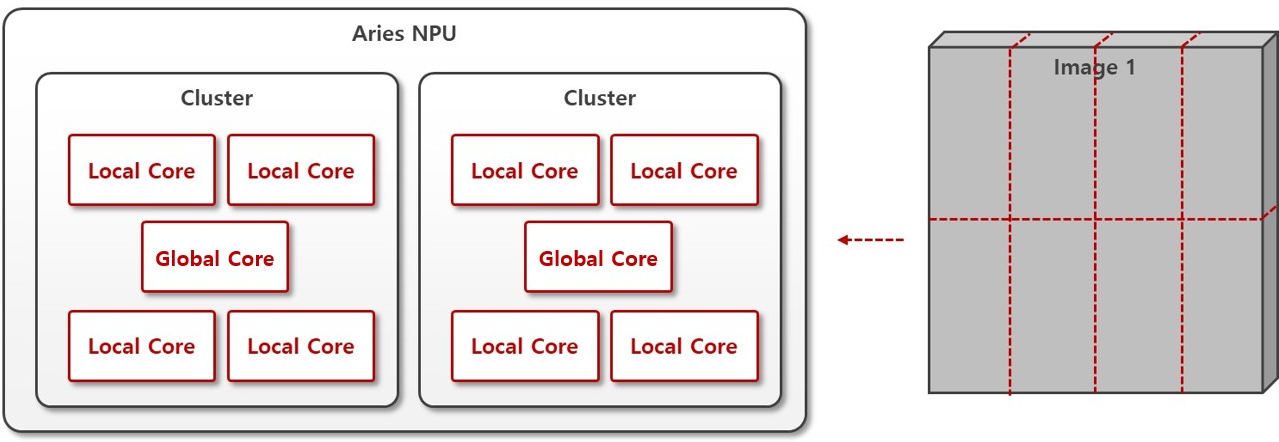
활용처
Latency 를 줄이고 싶은 모델
Global4 Mode#
4개의 Local Core (1개의 Cluster) 가 협동하여 한 개의 데이터를 처리합니다. 실행하고자 하는 클러스터 는 임의로 지정 가능합니다. 아래의 예시와 같이 컴파일하고 실행하면 됩니다.
## Compilation stage
# Generate MXQ Model with Global4 Inference Scheme
from qubee import mxq_compile
mxq_compile(
...
inference_scheme="global4"
...
)
## Runtime stage with python
# Run Global4 Type Model
from maccel import Accelerator, Model, ModelConfig, CoreId, Cluster, Core
MXQ_PATH = "resnet50_global4.mxq"
acc = Accelerator()
mc = ModelConfig()
mc.set_global4_core_mode([Cluster.Cluster1])
model = Model(MXQ_PATH, mc)
model.launch()
# model.infer(...)
// Runtime stage with C++
#include "maccel/maccel.h"
const char* MXQ_PATH = "resnet50_global4.mxq";
int main() {
mobilint::StatusCode sc;
mobilint::ModelConfig mc;
auto acc = mobilint::Accelerator::create(sc);
if (!sc) exit(1);
if (!mc.setGlobal4CoreMode({
mobilint::Cluster::Cluster1,
})) {
exit(1);
}
auto model = mobilint::Model::create(MXQ_PATH, mc, sc);
if (!sc) exit(1);
model->launch(*acc);
// auto result = model->infer();
}
Global8 Mode#
8개의 Local Core (2개의 Cluster) 가 협동하여 한 개의 데이터를 처리합니다. 아래의 예시와 같이 컴파일하고 실행하면 됩니다.
## Compilation stage
# Generate MXQ Model with Global8 Inference Scheme
from qubee import mxq_compile
mxq_compile(
...
inference_scheme="global8"
...
)
## Runtime stage with python
# Run Global8 Type Model
from maccel import Accelerator, Model, ModelConfig, CoreId, Cluster, Core
MXQ_PATH = "resnet50_global8.mxq"
acc = Accelerator()
mc = ModelConfig()
mc.set_global8_core_mode()
model = Model(MXQ_PATH, mc)
model.launch()
# model.infer(...)
// Runtime stage with C++
#include "maccel/maccel.h"
const char* MXQ_PATH = "resnet50_global8.mxq";
int main() {
mobilint::StatusCode sc;
mobilint::ModelConfig mc;
auto acc = mobilint::Accelerator::create(sc);
if (!sc) exit(1);
if (!mc.setGlobal8CoreMode()) {
exit(1);
}
auto model = mobilint::Model::create(MXQ_PATH, mc, sc);
if (!sc) exit(1);
model->launch(*acc);
// auto result = model->infer();
}